> For the complete documentation index, see [llms.txt](https://dezso.gitbook.io/dive-into-blockchian/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://dezso.gitbook.io/dive-into-blockchian/learnblockchain-12/learnethereum/geth-yuan-ma-jie-xi/vm-he-opcodes.md).
# VM与Opcodes
## 1)[Virtual Machine](https://github.com/DessertHeart/Dive-Into-Blockchain/blob/master/LearnBlockchain/LearnEthereum/geth源码解析/VM和Opcodes/\(https:/github.com/AmazingAng/WTF-Solidity/tree/main/Topics/Translation/DiveEVM2017\)/README.md)
**以太坊设计EVM的核心初衷**:
> V神:[以太坊设计原理](https://ethereumbuilders.gitbooks.io/guide/content/en/design_rationale.html)
1. EVM规范比其他许多虚拟机简单的多,因为其他虚拟机为复杂性付出的代价更小,也就是说它们更容易变得复杂;然而,在我们的方案中每额外增加一点复杂性,都会可能造成潜在的安全缺陷,比如造成共识失败,这就让我们的复杂性成本很高,因而不容易造成复杂;
2. EVM更加专业化,如支持32字节;
3. EVM没有复杂的外部依赖,复杂的外部依赖会导致我们安装失败,以太坊虚拟机运行在沙盒环境中,智能合约代码可在以太坊虚拟机内部运行并对外完全隔离,一定程度上提升了安全性;
4. 完善的审查机制,可以具体到特殊的安全需求。
### ①概念理解
Ethereum Virtual Machine 是所有以太坊帐户和智能合约依存的环境。从一个区块到另一个区块,EVM作为执行层,依照ETH协议层,计算了新的有效状态的规则。区别于普通的计算机(键盘、网络、鼠标等输入和显示器、打印机、网络等输出),它的输入输出很少。
* 输入:
* 另一个VM传来的函数调用所携带的数据
* EOA调用合约账户所携带的交易数据
* 输出
* 运行过程中修改的区块链账户的存储(Account State Storage)
* 日志Log
此外,如前文所述,在链上任何给定的区块处,以太坊有且只有一个“规范”状态,EVM 作为一个**堆栈机**运行的执行层,具有“确定性”的特点。
> 当输入确定的时候,EVM的输出无论重复多少次运行也是唯一不变的输出。所以在以太坊虚拟机中寻找一个随机源是很困难的。

* **合约调用合约的底层:**
以太坊中,执行代码的一台虚拟机可以启动另一台虚拟机来执行部分指令。这两台虚拟机都将在一个全节点上运行,形成多线程并行。这称之为“合约调用合约”。
> 如:合约A在执行计算时候需要调用 SafeMath 之类的安全数学计算库,而该库早已用合约的形式部署在以太坊网络上。 则该合约A可以通过直接调用SafeMath库合约为自己服务。
1. 在调用时发送方将发出 CALL的虚拟机指令,并将环境变量例如 `msg.sender` (此时为EOA)等设置好。
2. 启动另一台虚拟机运行被调用方的代码,得出结果后通过 `RETURN` 虚拟机指令发还给调用方的内存区,完成调用过程。

* **gas消耗:**
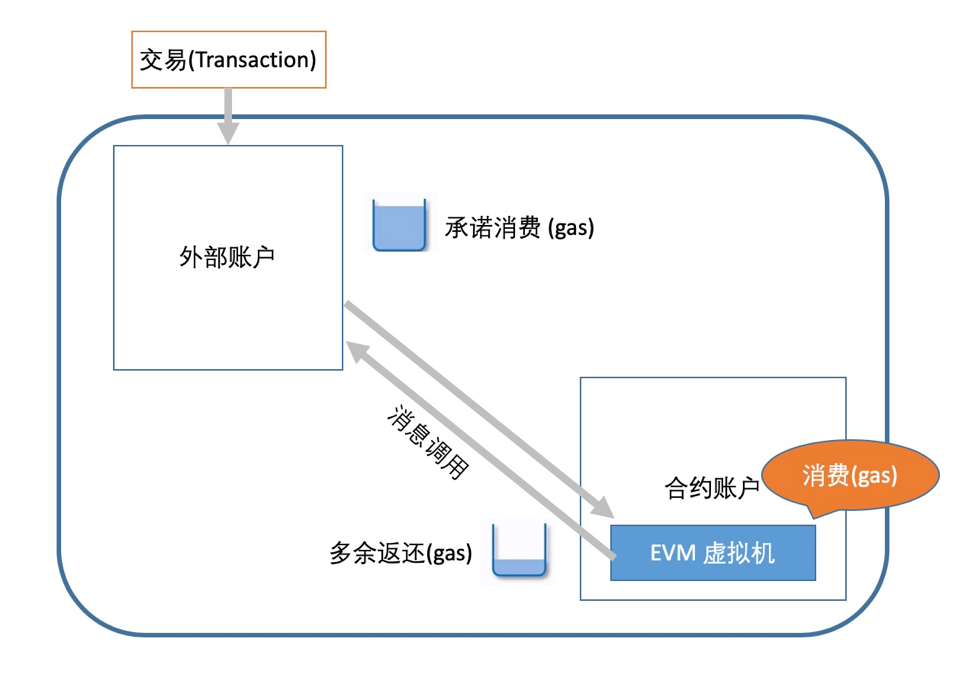
### ②源码分析
[EVM的内存结构](https://github.com/ZtesoftCS/go-ethereum-code-analysis/blob/master/core-vm-stack-memory%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90.md):
* Stack
```go
// core/vm/stack.go
// 实现了push、pop、dup、peek查看栈顶元素等方法
var stackPool = sync.Pool{
New: func() interface{} {
// 使用切片,初始化堆栈空间深度为 256B * 16
// 不同于以前直接分配1024深度的定长数组,优化内存分配
return &Stack{data: make([]uint256.Int, 0, 16)}
},
}
type Stack struct {
// package uint256:type Int [4]uint64
data []uint256.Int
}
func newstack() *Stack {
return stackPool.Get().(*Stack)
}
```
* Memory
```go
// core/vm/memory.go
// 实现了Resize分配空间、Set设置值、Get取值等方法
type Memory struct {
// 1B位宽,无线长度切片
store []byte
lastGasCost uint64
}
// NewMemory returns a new memory model.
func NewMemory() *Memory {
return &Memory{}
}
```
EVM的数据结构与初始化:
```go
// core/vm/evm.go
type EVM struct {
// 提供一些区块链信息辅助context
Context BlockContext
TxContext
// StateDB状态存储的接口,EVM大部分工作都是围绕其展开
StateDB StateDB
// 记录当前调用栈深度
depth int
// 记录链配置, 因为以太坊经历过几次的提案分叉,所以做了一些兼容
chainConfig *params.ChainConfig
// 标识符,判断链规则(同上原因)
chainRules params.Rules
// VM的配置,用于初始化
Config Config
// EVM解释器对象,它是整个VM执行代码、处理交易的地方
interpreter *EVMInterpreter
// 用于终止代码执行
abort int32
// 用于存储当前调用的gas可用值
callGasTemp uint64
}
func NewEVM(blockCtx BlockContext, txCtx TxContext, statedb StateDB, chainConfig *params.ChainConfig, config Config) *EVM {
evm := &EVM{
Context: blockCtx,
TxContext: txCtx,
StateDB: statedb,
Config: config,
chainConfig: chainConfig,
chainRules: chainConfig.Rules(blockCtx.BlockNumber, blockCtx.Random != nil),
}
// 重点是创建解释器,解释器是执行字节码的关键
evm.interpreter = NewEVMInterpreter(evm, config)
return evm
}
```
EVM解释器Interpreter的创建初始化流程,主要是对Opcodes根据不同分叉版本的适配管理:
```go
// core/vm/interpreter.go
func NewEVMInterpreter(evm *EVM, cfg Config) *EVMInterpreter {
// 设置操作码对应的函数
// JumpTable即管理着EVM opcodes
// 同样因为以太坊经历版本迭代之后,操作码有了一些变化,所以有多个情况
if cfg.JumpTable == nil {
switch {
case evm.chainRules.IsMerge:
cfg.JumpTable = &mergeInstructionSet
case evm.chainRules.IsLondon:
cfg.JumpTable = &londonInstructionSet
case evm.chainRules.IsBerlin:
cfg.JumpTable = &berlinInstructionSet
case evm.chainRules.IsIstanbul:
cfg.JumpTable = &istanbulInstructionSet
case evm.chainRules.IsConstantinople:
cfg.JumpTable = &constantinopleInstructionSet
case evm.chainRules.IsByzantium:
cfg.JumpTable = &byzantiumInstructionSet
case evm.chainRules.IsEIP158:
cfg.JumpTable = &spuriousDragonInstructionSet
case evm.chainRules.IsEIP150:
cfg.JumpTable = &tangerineWhistleInstructionSet
case evm.chainRules.IsHomestead:
cfg.JumpTable = &homesteadInstructionSet
default:
cfg.JumpTable = &frontierInstructionSet
}
var extraEips []int
if len(cfg.ExtraEips) > 0 {
// Deep-copy jumptable to prevent modification of opcodes in other tables
cfg.JumpTable = copyJumpTable(cfg.JumpTable)
}
for _, eip := range cfg.ExtraEips {
if err := EnableEIP(eip, cfg.JumpTable); err != nil {
// Disable it, so caller can check if it's activated or not
log.Error("EIP activation failed", "eip", eip, "error", err)
} else {
extraEips = append(extraEips, eip)
}
}
cfg.ExtraEips = extraEips
}
return &EVMInterpreter{
evm: evm,
cfg: cfg,
}
}
```
回到EVM的初始化入口。
Ethereum的虚拟机源码所有部分在core/vm下。EVM的调用的入口在`core/state_transition.go`目录中
```go
// StateTransition 是当一笔交易应用于当前的世界状态时所产生的一个“变化change”
// 负责完成所有状态变化所对应的步骤,并最终生成新的 state trie root
func (st *StateTransition) TransitionDb() (*ExecutionResult, error) {
......
// evm的入口
// contractCreation = msg.To() == nil
// 即如果交易的接受者为0地址,则判断为合约创建类型
if contractCreation {
// evm.Create()
// 合约部署的 Code 同样通过transaction的data字段传入
// data的构造包括:部署代码 (creation code)、合约代码 (runtime code)、(可选)辅助数据 (Auxdata)
// demo:https://github.com/AmazingAng/WTF- Solidity/blob/main/Topics/Translation/DiveEVM2017/DiveEVM2017-Part5.md
ret, _, st.gas, vmerr = st.evm.Create(sender, st.data, st.gas, st.value)
} else {
// 增加nonce值(防止重放攻击),为下一笔交易做准备
st.state.SetNonce(msg.From(), st.state.GetNonce(sender.Address())+1)
// evm.Call()
ret, st.gas, vmerr = st.evm.Call(sender, st.to(), st.data, st.gas, st.value)
}
......
return &ExecutionResult{
UsedGas: st.gasUsed(),
Err: vmerr,
ReturnData: ret,
}, nil
}
```
* 合约部署:`evm.Create() => evm.interpreter.Run()`
```go
// core/vm/evm.go
func (evm *EVM) Create(caller ContractRef, code []byte, gas uint64, value *big.Int) (ret []byte, contractAddr common.Address, leftOverGas uint64, err error) {
// 根据caller.address与caller.nonce生成合约地址
contractAddr = crypto.CreateAddress(caller.Address(), evm.StateDB.GetNonce(caller.Address()))
// 从这上下两步可以看出,在合约创建初始化完成之前,合约地址已经生成了
// 即对应solidity的constructor()阶段,code还没建立,但是可以取到address(this)的
return evm.create(caller, &codeAndHash{code: code}, gas, value, contractAddr, CREATE)
}
// EVM通过运行creation code部署并初始化合约,把runtime的合约代码返回并设置到合约地址
func (evm *EVM) create(caller ContractRef, codeAndHash *codeAndHash, gas uint64, value *big.Int, address common.Address, typ OpCode) ([]byte, common.Address, uint64, error) {
// 检测当前evm执行的深度,默认不应该超过1024
if evm.depth > int(params.CallCreateDepth) {
return nil, common.Address{}, gas, ErrDepth
}
// 检测是否调用方的金额大约value
if !evm.Context.CanTransfer(evm.StateDB, caller.Address(), value) {
return nil, common.Address{}, gas, ErrInsufficientBalance
}
// 首先获取调用者的nonce,然后nonce+1
nonce := evm.StateDB.GetNonce(caller.Address())
if nonce+1 < nonce {
return nil, common.Address{}, gas, ErrNonceUintOverflow
}
evm.StateDB.SetNonce(caller.Address(), nonce+1)
// contract address加入到access list
// 这个行为不需要也不该被回滚
if evm.chainRules.IsBerlin {
evm.StateDB.AddAddressToAccessList(address)
}
// 确定指定的合约地址是唯一的
contractHash := evm.StateDB.GetCodeHash(address)
if evm.StateDB.GetNonce(address) != 0 || (contractHash != (common.Hash{}) && contractHash != emptyCodeHash) {
return nil, common.Address{}, 0, ErrContractAddressCollision
}
// 为合约地址在世界状态上层封装的stateDB中创建账户体系
snapshot := evm.StateDB.Snapshot()
evm.StateDB.CreateAccount(address)
if evm.chainRules.IsEIP158 {
evm.StateDB.SetNonce(address, 1)
}
evm.Context.Transfer(evm.StateDB, caller.Address(), address, value)
// 创建一个合约对象,并设置合约对象的参数,比如runtime code等
// 参照core/vm/contract.go,contract代表以太坊stateDB里面的一个合约对象
contract := NewContract(caller, AccountRef(address), value, gas)
contract.SetCodeOptionalHash(&address, codeAndHash)
if evm.Config.Debug {
if evm.depth == 0 {
evm.Config.Tracer.CaptureStart(evm, caller.Address(), address, true, codeAndHash.code, gas, value)
} else {
evm.Config.Tracer.CaptureEnter(typ, caller.Address(), address, codeAndHash.code, gas, value)
}
}
start := time.Now()
// 核心:将合约对象传入解释器Run函数开始执行
// 该函数为真正执行合约代码的地方
// evm.Call()入口进入的时候最终也会调用此函数
ret, err := evm.interpreter.Run(contract, nil, false)
// 下面的流程主要是一些协议检查
// Check whether the max code size has been exceeded, assign err if the case.
if err == nil && evm.chainRules.IsEIP158 && len(ret) > params.MaxCodeSize {
err = ErrMaxCodeSizeExceeded
}
// Reject code starting with 0xEF if EIP-3541 is enabled.
if err == nil && len(ret) >= 1 && ret[0] == 0xEF && evm.chainRules.IsLondon {
err = ErrInvalidCode
}
// 如果creationCode执行成功,则在stateDB中把返回的字节码(runtime code)
// 保存到此合约账户(上面创建的)名下,这样之后调用合约代码才能加载成功
// If the code could not
// be stored due to not enough gas set an error and let it be handled
// by the error checking condition below.
if err == nil {
createDataGas := uint64(len(ret)) * params.CreateDataGas
if contract.UseGas(createDataGas) {
evm.StateDB.SetCode(address, ret)
} else {
err = ErrCodeStoreOutOfGas
}
}
// 如果发生任何错误,revert世界状态state至改变之前(通过snapshot)
// 如果err不是ErrExecutionReverted错误,则消耗掉所有gas
if err != nil && (evm.chainRules.IsHomestead || err != ErrCodeStoreOutOfGas) {
evm.StateDB.RevertToSnapshot(snapshot)
if err != ErrExecutionReverted {
contract.UseGas(contract.Gas)
}
}
if evm.Config.Debug {
if evm.depth == 0 {
evm.Config.Tracer.CaptureEnd(ret, gas-contract.Gas, time.Since(start), err)
} else {
evm.Config.Tracer.CaptureExit(ret, gas-contract.Gas, err)
}
}
return ret, address, contract.Gas, err
}
```
```go
// core/vm/interpreter.go
// 运行代码loops并评估在给定input data情况下合约代码的执行情况,返回[]byte或error
// 除了ErrExecutionReverted(solidity:revert)错误会返还gas剩余给caller
// 其他解释器返回的错误都视为revert-and-consume-all-gas
func (in *EVMInterpreter) Run(contract *Contract, input []byte, readOnly bool) (ret []byte, err error) {
// 增加1堆栈深度,最大1024
in.evm.depth++
defer func() { in.evm.depth-- }()
......
// 下面的变量满足了一个字节码执行的所有条件
// 有操作码、内存、栈、PC程序计数器
// debug工具是用于跟踪执行的流程状态,运行时建议使用
var (
op OpCode // current opcode
mem = NewMemory() // bound memory
stack = newstack() // local stack
callContext = &ScopeContext{
Memory: mem,
Stack: stack,
Contract: contract,
}
// For optimisation reason we're using uint64 as the program counter.
// It's theoretically possible to go above 2^64. The YP defines the PC
// to be uint256. Practically much less so feasible.
pc = uint64(0) // program counter
cost uint64
// copies used by tracer
pcCopy uint64 // needed for the deferred EVMLogger
gasCopy uint64 // for EVMLogger to log gas remaining before execution
logged bool // deferred EVMLogger should ignore already logged steps
res []byte // opcode执行函数返回的结果
)
// Don't move this deferred function, it's placed before the capturestate-deferred method,
// so that it get's executed _after_: the capturestate needs the stacks before
// they are returned to the pools
defer func() {
returnStack(stack)
}()
contract.Input = input
......
// 解释器执行opcodes的入口loop
// 持续执行直到 STOP, RETURN 或 SELFDESTRUCT
for {
if in.cfg.Debug {
// Capture pre-execution values for tracing.
logged, pcCopy, gasCopy = false, pc, contract.Gas
}
// 根据根据PC计数器获取操作码,根据操作码从JumpTable获取对应的操作函数
op = contract.GetOp(pc)
operation := in.cfg.JumpTable[op]
cost = operation.constantGas // For tracing
// 确保有足够的stack空间执行
if sLen := stack.len(); sLen < operation.minStack {
return nil, &ErrStackUnderflow{stackLen: sLen, required: operation.minStack}
} else if sLen > operation.maxStack {
return nil, &ErrStackOverflow{stackLen: sLen, limit: operation.maxStack}
}
if !contract.UseGas(cost) {
return nil, ErrOutOfGas
}
if operation.dynamicGas != nil {
// 有些指令是需要额外的内存消耗,但并不是所有的指令
// 在jump_table.go文件中可以看到他们具体每个操作码的对应的额外内存消耗计算
// memorySize指向对应的计算消耗内存的函数,根据消耗的内存来计算消费的gas
var memorySize uint64
if operation.memorySize != nil {
memSize, overflow := operation.memorySize(stack)
if overflow {
return nil, ErrGasUintOverflow
}
// memory is expanded in words of 32 bytes. Gas
// is also calculated in words.
if memorySize, overflow = math.SafeMul(toWordSize(memSize), 32); overflow {
return nil, ErrGasUintOverflow
}
}
// 计算此操作花费的gas数量,可用gas不足会抛出错误
var dynamicCost uint64
dynamicCost, err = operation.dynamicGas(in.evm, contract, stack, mem, memorySize)
cost += dynamicCost // for tracing
if err != nil || !contract.UseGas(dynamicCost) {
return nil, ErrOutOfGas
}
// Do tracing before memory expansion
if in.cfg.Debug {
in.cfg.Tracer.CaptureState(pc, op, gasCopy, cost, callContext, in.returnData, in.evm.depth, err)
logged = true
}
if memorySize > 0 {
mem.Resize(memorySize)
}
} else if in.cfg.Debug {
in.cfg.Tracer.CaptureState(pc, op, gasCopy, cost, callContext, in.returnData, in.evm.depth, err)
logged = true
}
// 开始执行此操作码对应的操作函数
// 操作码对应的操作函数都是在core/vm/opcodes.go中
res, err = operation.execute(&pc, in, callContext)
// 只有遇到err才会终止运行,其他的Opcodes都会返回nil
// 注意即使是selfdestruct、revert或stop正常结束也会以err形式返回
if err != nil {
break
}
// 更新PC计数器,继续loops
pc++
}
......
return res, err
}
```
到了这里整个部署合约流程就完成了,回到`evm.Create`函数中可以看到了当run执行完成后会把runtime code最终设置到合约地址名下(opcodes会执行`codeCopy`指令后把runtime code从内input data加载到内存并返回),整个合约部署就算完成了。
* 合约调用:`evm.Call() => evm.interpreter.Run()`
调用智能合约和部署合约,在EVM看来就是交易的to地址不在`nil`而是一个具体的合约地址。 同时input data不再是整个合约编译后的字节码了而是调用函数和对应的实参组合。 这里就涉及到另一个东西那就是abi的概念(可查看编码方式章节)。
```go
// core/vm/evm.go
func (evm *EVM) Call(caller ContractRef, addr common.Address, input []byte, gas uint64, value *big.Int) (ret []byte, leftOverGas uint64, err error) {
// stack深度检查
if evm.depth > int(params.CallCreateDepth) {
return nil, gas, ErrDepth
}
// 账户余额检查
if value.Sign() != 0 && !evm.Context.CanTransfer(evm.StateDB, caller.Address(), value) {
return nil, gas, ErrInsufficientBalance
}
snapshot := evm.StateDB.Snapshot()
p, isPrecompile := evm.precompile(addr)
// 判断这个合约地址是否存在,如果不存在是否是内置(预编译)合约
if !evm.StateDB.Exist(addr) {
if !isPrecompile && evm.chainRules.IsEIP158 && value.Sign() == 0 {
// Calling a non existing account, don't do anything, but ping the tracer
if evm.Config.Debug {
if evm.depth == 0 {
evm.Config.Tracer.CaptureStart(evm, caller.Address(), addr, false, input, gas, value)
evm.Config.Tracer.CaptureEnd(ret, 0, 0, nil)
} else {
evm.Config.Tracer.CaptureEnter(CALL, caller.Address(), addr, input, gas, value)
evm.Config.Tracer.CaptureExit(ret, 0, nil)
}
}
return nil, gas, nil
}
evm.StateDB.CreateAccount(addr)
}
// 执行 ETH Token转账
evm.Context.Transfer(evm.StateDB, caller.Address(), addr, value)
......
if isPrecompile {
ret, gas, err = RunPrecompiledContract(p, input, gas)
} else {
// Initialise a new contract and set the code that is to be used by the EVM.
// The contract is a scoped environment for this execution context only.
code := evm.StateDB.GetCode(addr)
if len(code) == 0 {
ret, err = nil, nil // gas is unchanged
} else {
addrCopy := addr
// 不管是部署合约还是调用合约都要先创建合约对象用例,把存储中合约code加载出来挂到合约对象下
// 这里可以看到,CALL指令执行时会创建新的Contract对象,并以内存中的调用参数作为其Input
// (区别于delegatecall、callcode的实现,会将object contract也配置为caller contract)
// 解释器会为新合约的执行创建新的Stack和Memory,从而不会破环原合约的执行环境
contract := NewContract(caller, AccountRef(addrCopy), value, gas)
contract.SetCallCode(&addrCopy, evm.StateDB.GetCodeHash(addrCopy), code)
// 依然是调用解释器的run函数来执行代码,不同之处在于这次的input不在是nil了,而是交易的input内容
// 正如前面提到,input会在交易的data中,CALLDATALOAD这个指令会用于加载input的内容
ret, err = evm.interpreter.Run(contract, input, false)
gas = contract.Gas
}
}
// 如果发生任何错误,revert世界状态state至改变之前(通过snapshot)
// 如果不是ErrExecutionReverted错误,则消耗掉所有gas
if err != nil {
evm.StateDB.RevertToSnapshot(snapshot)
if err != ErrExecutionReverted {
gas = 0
}
}
return ret, gas, err
}
```
## 2)字节码Opcodes指令
### ①源码分析
EVM的操作码和其他汇编语言的指令码类似。 只是一般的CPU是基于寄存器的[哈弗架构或者冯诺依曼架构](https://zhuanlan.zhihu.com/p/85847486)。 EVM是基于栈式结构,大端序(数据的低位字节存放在内存的高位地址,高位字节存放在低位地)的256bit的虚拟机。 每一个字节码是一个字节。
`jump_table` 是一个 `[256]*operation` 的数据结构。每个下标对应了一种指令,使用operation来存储了指令对应的处理逻辑、gas消耗、 堆栈验证方法、memory使用的大小等功能,数据结构`operation`存储了一条指令的所需要的属性和方法。
```go
// core/vm/jump_table.go
// JumpTable contains the EVM opcodes supported at a given fork.
type JumpTable [256]*operation
// operation
type operation struct {
// 执行函数
execute executionFunc
// operation所消耗gas固定值
constantGas uint64
// 预留gas实际动态消耗计算函数
dynamicGas gasFunc
// 本次operation所需最小stack空间
minStack int
// 能为本次operation分配的最大stack空间
maxStack int
// 计算本次operation所需的内存大小的函数
memorySize memorySizeFunc
}
// 不同版本指令集,针对不同的以太坊版本
var (
frontierInstructionSet = newFrontierInstructionSet()
homesteadInstructionSet = newHomesteadInstructionSet()
tangerineWhistleInstructionSet = newTangerineWhistleInstructionSet()
spuriousDragonInstructionSet = newSpuriousDragonInstructionSet()
byzantiumInstructionSet = newByzantiumInstructionSet()
constantinopleInstructionSet = newConstantinopleInstructionSet()
istanbulInstructionSet = newIstanbulInstructionSet()
berlinInstructionSet = newBerlinInstructionSet()
londonInstructionSet = newLondonInstructionSet()
mergeInstructionSet = newMergeInstructionSet()
)
```
### ②Opcodes学习(结合Solidity)
> Opcodes的定义可见:`core/vm/opcodes.go`
> [Opcodes指令集](https://www.evm.codes/):opcode的长度为1个字节也就是最多支持256种opcode,现在EVM已使用140种(*2022.12*)
**知识点实例一:内存数据长度(length)**
> ```solidity
> bytes memory data = 0x1234;
> uint size = data.length;
> assembly{
> pop(call(gas(), addr, 0, add(data, 0x20), size, 0,0))
> }
> ```
>
> 对于动态数组如bytes/string类型,solidity编译时,data指针指向的是内存数据块的**长度**,而紧接着的data+0x20指针指向的是内存数据库开始位置处,故这里作了`add(data, 0x20)`处理
**知识点实例二:**[**内存布局(layout in memory)与空闲指针(Free Memory Pointer)**](https://learnblockchain.cn/article/3684)
> Solidity的内存布局保留了4个32字节的插槽:
>
> * 0x00 - 0x3f (64 bytes): scratch space:哈希计算方法的预留空间,以便在inline assembly可以使用方法
> * 0x40 - 0x5f (32 bytes): free memory pointer
> * 0x60 - 0x7f (32 bytes): zero slot:被用作动态内存数组的初始值,永远不能被写入
>
> 可以看到,0x40是solidity为freeMemoryPointer预留的位置。值0x80只是在4个保留的32字节的插槽之后第一个可写的位置。
Free Memory Pointer是一个指向自由内存开始位置的指针。它确保智能合约知道已写入和未写入的内存位置。 这可以防止合约覆盖一些已经分配给另一个变量的内存。 当一个变量被写入内存时,合约将首先参考Free Memory Pointer,以确定数据应该被存储在哪里。 然后,它更新Free Memory Pointer,指出有多少数据将被写入新的位置。这两个值的简单相加将产生新的自由内存的起始位置。
`freeMemoryPointer + dataSizeBytes(数据大小) = newFreeMemoryPointer`
**Solidity 通过free Memory Pointer管理内存,如果要分配内存,需从此指针指向的位置开始使用内存并更新内存**
* **1、初始化:**
```
60 80 = PUSH1 0x80
60 40 = PUSH1 0x40
52 = MSTORE
```
实际上说明了free Memory Pointer在内存中位于memory中的0x40(十进制:64)位置,其值为0x80(十进制128)。
* **2、**[**使用**](https://ethereum.stackexchange.com/questions/70839/how-does-this-assembly-code-create-a-new-memory-end)
* 读取当前free pointer memory指向的位置
```
// 伪代码
array_memory = memory[0x40]
// Yul
mload(0x40)
```
* 本次使用`code`大小过后,计算并更新free pointer memory下一个要指向的值
```
// 要考虑code长度额外的32字节,并最终将其向上取整32字节。
// 数学公式: trunc((code_size + 32 + 32-1)/32) * 32
// 伪代码
array_size = (code_size + 0x20 + 0x1f) & ~0x1f
// Yul
mstore(0x40, add(code, and(add(add(size, 0x20), 0x1f), not(0x1f))))
```
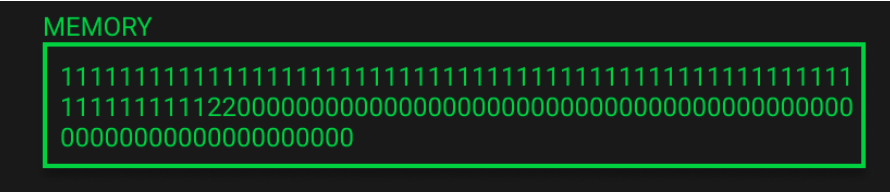
**知识点实例三:内存拓展(memory expansion)**
> (32字节的数据为右对齐)
>
> 当合约写内存时,你必须为所写的字节数付费。如果写到一个以前没有被写过的内存区域,那么第一次使用该区域会有一个额外的内存扩展费用。 所以,当写到以前未使用的内存空间时,EVM会直接讲内存以32字节(256位)的增量进行扩展。
>
>  >
> 当再写入一个单字节数据0x22,即使MSTORE8写到内存中后,结果也是如图
>
>
>
> 当再写入一个单字节数据0x22,即使MSTORE8写到内存中后,结果也是如图
>
>  **知识点实例四:负整数(Negative integers)与溢出管理**
> 负整数通常使用[二进制补码](https://www.cnblogs.com/zhangziqiu/archive/2011/03/30/computercode.html)的方式表示。 int8 编码类型的值 `-1` 将全部为 1 `1111 1111`。
>
> ABI 用 1 填充负整数,因此 `-1` 将被填充为:
>
> `ffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff`
>
> 注意:小的负数大部分是 1,这会花费很多 gas
>
> **EVM在处理溢出问题时直接对溢出位进行舍弃,对结果进行取模(默认modulo为2^256 )**
**知识点实例五:Opcodes执行环境**
当 EVM 执行智能合约时,将为其创建context执行上下文环境。context由几个内存区域组成,每个区域都有自己的用途,如下:
> * **The Code**:
>
> account code的存储区域,它是持久性的,是帐户属性的一部分(对应accountState的字段)。在智能合约执行期间,EVM 将读取、解释和执行这些字节码。code是只读的,但可以使用指令 `CODESIZE` 和 `CODECOPY` 读取该区域。其他合约也可以用 `EXTCODESIZE` 和 `EXTCODECOPY` 读取。EOA该区域为空。
>
> * **The Stack**:
>
> 一个包含32字节\*1024元素的列表。堆栈用于放置指令所需的参数及其结果值。当一个新的值被放到堆栈上时,它被放到顶部,并且指令只使用顶部的值(前文也多次详述)。
>
> * **The Memory**:
>
> 一个只在智能合约执行期间存在的字节数组,以32字节为单位扩展,以通过`offset` (字节偏移量) 访问。每个字节初始化为0,但不管是否使用,大小将按访问的最大值计数。通常使用 `MLOAD` 和 `MSTORE` 指令来读写,但也被其他指令如 `CREATE` 或 `EXTCODECOPY`使用。
>
> * **The Storage**:
>
> 对应Solidity[动态类型的存储规则](https://github.com/AmazingAng/WTF-Solidity/blob/main/Topics/Translation/DiveEVM2017/DiveEVM2017-Part3.md)
>
> * map:存储于第position位置slot的map,其value的存储位置默认为`slot[keccak256(bytes32(key) + bytes32(position))]`,因为每个slot只有 32 个字节,如果value超过32字节(比如struct),超出的部分存储于上述keccak计算结果+1(以32字节为单位递增)的位置
> * slice:原slot\[position]位置存储slice.length,下标0的元素存储于`slot[keccak256(bytes32(position))]`,下标index存储于`slot[keccak256(bytes32(position)) + 1]`
>
> 智能合约的持久化存储区域,对应account Storage Trie中每个账户的storage空间。它是32字节到32字节值的映射,保留写入的每个值直到将其设置为0或`SELFDESTRUCT`。读取未设置过的键也会返回0。通过 `SLOAD` 和 `SSTORE` 指令读写。[**此外,storage在EVM中存储时存在32字节紧打包优化**](https://learnblockchain.cn/docs/solidity/internals/layout_in_storage.html)
>
> * **The Calldata**:
>
> 存储的是跟随transaction一起发送的数据。在创建合约时,它是存储creation code (构造函数代码)。同样该区域是不可改变的,可以通过使用 `CALLDATASIZE` 的 `CALLDATALOAD` 和 `CALLDATaCOPY` 指令来读取。
>
> * **The Return Data**:
>
> 存储智能合约在调用后返回的值。将存储通过 `RETURN` 和 `REVERT` 指令调用外部合约后,外部合约的返回值。也可以在本合约通过使用 `RETURNDATASIZE` 和 `RETURNDATACOPY` 指令读取。
**知识点实例六:**[**预编译合约(Precompiled Contract)**](https://www.evm.codes/precompiled)
`core/vm/contracts.go`
EVM 通过预编译合约提供了一组更高级的功能,并且可以避免常用的复杂计算所带来的代价。预编译合约是一种特殊的合约,有固定的地址和固定的gas消耗(合约自身内部代码执行的消耗,并不考虑 `CALL` 行为本身所带来的gas消耗)。其在opcodes中的使用方式、调用方式如普通合约一样,通过如 `CALL`这样的指令 。
另外在输入参数方面,对于所有预编译合约,如果输入比预期的要短,则默认用0填充。如果输入比预期的长,则忽略末尾多余的字节。另外在 **Berlin分叉** 之后,所有预编译的合约地址总是被认为是 'warm' (access set)。
> 注:Solidity中的`keccak256`是EVM内部实现的SHA3系列,未通过预编译合约形式
>
> 其它两个哈希算法虽然没怎么用到,但源于以太坊一开始是基于比特币设计的,黄皮书中有定义,故而保留(注:SHA256属于SHA2-family)
>
>
**知识点实例四:负整数(Negative integers)与溢出管理**
> 负整数通常使用[二进制补码](https://www.cnblogs.com/zhangziqiu/archive/2011/03/30/computercode.html)的方式表示。 int8 编码类型的值 `-1` 将全部为 1 `1111 1111`。
>
> ABI 用 1 填充负整数,因此 `-1` 将被填充为:
>
> `ffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff`
>
> 注意:小的负数大部分是 1,这会花费很多 gas
>
> **EVM在处理溢出问题时直接对溢出位进行舍弃,对结果进行取模(默认modulo为2^256 )**
**知识点实例五:Opcodes执行环境**
当 EVM 执行智能合约时,将为其创建context执行上下文环境。context由几个内存区域组成,每个区域都有自己的用途,如下:
> * **The Code**:
>
> account code的存储区域,它是持久性的,是帐户属性的一部分(对应accountState的字段)。在智能合约执行期间,EVM 将读取、解释和执行这些字节码。code是只读的,但可以使用指令 `CODESIZE` 和 `CODECOPY` 读取该区域。其他合约也可以用 `EXTCODESIZE` 和 `EXTCODECOPY` 读取。EOA该区域为空。
>
> * **The Stack**:
>
> 一个包含32字节\*1024元素的列表。堆栈用于放置指令所需的参数及其结果值。当一个新的值被放到堆栈上时,它被放到顶部,并且指令只使用顶部的值(前文也多次详述)。
>
> * **The Memory**:
>
> 一个只在智能合约执行期间存在的字节数组,以32字节为单位扩展,以通过`offset` (字节偏移量) 访问。每个字节初始化为0,但不管是否使用,大小将按访问的最大值计数。通常使用 `MLOAD` 和 `MSTORE` 指令来读写,但也被其他指令如 `CREATE` 或 `EXTCODECOPY`使用。
>
> * **The Storage**:
>
> 对应Solidity[动态类型的存储规则](https://github.com/AmazingAng/WTF-Solidity/blob/main/Topics/Translation/DiveEVM2017/DiveEVM2017-Part3.md)
>
> * map:存储于第position位置slot的map,其value的存储位置默认为`slot[keccak256(bytes32(key) + bytes32(position))]`,因为每个slot只有 32 个字节,如果value超过32字节(比如struct),超出的部分存储于上述keccak计算结果+1(以32字节为单位递增)的位置
> * slice:原slot\[position]位置存储slice.length,下标0的元素存储于`slot[keccak256(bytes32(position))]`,下标index存储于`slot[keccak256(bytes32(position)) + 1]`
>
> 智能合约的持久化存储区域,对应account Storage Trie中每个账户的storage空间。它是32字节到32字节值的映射,保留写入的每个值直到将其设置为0或`SELFDESTRUCT`。读取未设置过的键也会返回0。通过 `SLOAD` 和 `SSTORE` 指令读写。[**此外,storage在EVM中存储时存在32字节紧打包优化**](https://learnblockchain.cn/docs/solidity/internals/layout_in_storage.html)
>
> * **The Calldata**:
>
> 存储的是跟随transaction一起发送的数据。在创建合约时,它是存储creation code (构造函数代码)。同样该区域是不可改变的,可以通过使用 `CALLDATASIZE` 的 `CALLDATALOAD` 和 `CALLDATaCOPY` 指令来读取。
>
> * **The Return Data**:
>
> 存储智能合约在调用后返回的值。将存储通过 `RETURN` 和 `REVERT` 指令调用外部合约后,外部合约的返回值。也可以在本合约通过使用 `RETURNDATASIZE` 和 `RETURNDATACOPY` 指令读取。
**知识点实例六:**[**预编译合约(Precompiled Contract)**](https://www.evm.codes/precompiled)
`core/vm/contracts.go`
EVM 通过预编译合约提供了一组更高级的功能,并且可以避免常用的复杂计算所带来的代价。预编译合约是一种特殊的合约,有固定的地址和固定的gas消耗(合约自身内部代码执行的消耗,并不考虑 `CALL` 行为本身所带来的gas消耗)。其在opcodes中的使用方式、调用方式如普通合约一样,通过如 `CALL`这样的指令 。
另外在输入参数方面,对于所有预编译合约,如果输入比预期的要短,则默认用0填充。如果输入比预期的长,则忽略末尾多余的字节。另外在 **Berlin分叉** 之后,所有预编译的合约地址总是被认为是 'warm' (access set)。
> 注:Solidity中的`keccak256`是EVM内部实现的SHA3系列,未通过预编译合约形式
>
> 其它两个哈希算法虽然没怎么用到,但源于以太坊一开始是基于比特币设计的,黄皮书中有定义,故而保留(注:SHA256属于SHA2-family)
>
>  >
> 哈希算法的三个特性:
>
> 1. **唯一性**:输入任意内容可输出定长的内容,相同的输入一定会产出相同的输出,抗[碰撞](https://www.ruanyifeng.com/blog/2018/09/hash-collision-and-birthday-attack.html);
> 2. **雪崩效应**:即使一个极小的改变都会产生几乎完全不同的哈希值;
> 3. **单向性**:无法反向推导出pre-image(被哈希的内容的)。
| Address | Name | Description | Input(默认从左向右为:栈顶 => 向下) | Output | Gas |
| :-----: | :--------: | -------------------------------------------------------------------------------------------------------------------- | :-----------------------: | :-------: | :----: |
| `0x01` | ecRecover | 通过`signed transaction hash`及签名`v,r,s`,进行椭圆曲线数字签名算法(ECDSA)公钥恢复`signer address`,gas不足返回值为空 | `txhash,v,r,s` | `address` | 3000 |
| `0x02` | SHA2-256 | SHA256哈希算法(Bitcoin使用,属于SHA2系列),产生256位输出,gas不足返回值为空,对应Solidity中`sha256` | `data` | `hash` | 60+ |
| `0x03` | RIPEMD-160 | RIPEMD-160哈希算法 (Bitcoin使用),产生160位输出,gas不足返回值为空,对应Solidity中`ripemd160` | `data` | `hash` | 600+ |
| `0x04` | identity | 返回输入的`data`,通常用于复制内存块,gas不足返回值为空 | `data` | `data` | 15+ |
| `0x05` | modexp | 计算 $B^{E}\ mod \ M$ (`B/E/Msize`为对应值所占字节大小)的任意精度指数,E为0固定返回1,M为1固定返回0,gas不足返回值为空 | `Bsize,Esize,Msize,B,E,M` | `value` | 200+ |
| `0x06` | ecAdd | 椭圆曲线'alt\_bn128'上两点 (x,y) 的相加(ADD),无穷远点的 x 和 y 均为0,入参无效或gas不足返回值为空 | `x1,y1,x2,y2` | `x,y` | 150+ |
| `0x07` | ecMul | BN128椭圆曲线上点与标量相乘(MUL),s为标量scalar,无穷远点的 x 和 y 均为0 | `x1,y1,s` | `x,y` | 6000+ |
| `0x08` | ecPairing | BN128椭圆曲线的双线性函数配对操作,将用于[zk-SNARK](https://www.8btc.com/article/6783962)验证,入参无效或gas不足返回值为空 | `x1,y1,x2,y2...xk,yk` | `success` | 45000+ |
| `0x09` | blake2f | 实现blake2哈希函数,并在 BLAKE2 哈希算法中使用压缩函数 F ,使用的次数`rounds`([大端对齐](https://www.ruanyifeng.com/blog/2016/11/byte-order.html)) | `rounds,h,m,t,f` | `h` | 0+ |
**定义类知识点:**
* **Empty Account**:如果帐户的balance为0,nonce 为0且没有code,则定于该帐户为空账户
* **Intrinsic Gas**:每笔transaction的 “基本花销” 为21000 gas。在该基础上,部署一个contract需要花费 “基本花销” 32000 gas。之后,对于calldata,每0字节花费4gas,非0则花费16gas( **Istanbul分叉**之前是64gas)。这些费用需在执行任何opcodes或transfer之前被支付。
* **Gas Refund**:部分opcodes可以触发gas refund,从而降低交易的gas成本。然而,gas refund是在一笔transaction最后执行,这意味着transaction仍然需要足够的gas来运行完成(就好像不存在gas refund一样)。
此外,可以退还的gas数量也是有限的,不能超过整个transaction成本的一半(**London分叉**前),现在不能超过五分之一。并且从**London分叉**开始,只有 `SSTORE` 可能会触发gas refund,在此之前,SELFDESTRCT 也可以。
* [**Access Set**](https://github.com/wolflo/evm-opcodes/blob/main/gas.md):**Berlin分叉**后出现的概念,存在于access set的地址标识为'warm',不存在则标识为'cold',一些opcodes的动态开销与其有关。access set与每笔transaction绑定(而不是调用context)。access set中存在两个变量如下:
```go
// eth/tracers/loggers/access_list_tracer.go
type AccessListTracer struct {
excl map[common.Address]struct{} // Set of account to exclude from the list
list accessList // Set of accounts and storage slots touched
}
```
* **touched\_addresses**:存储一组当前transaction中被访问过的contract address。它被初始化为sender、receiver (CA/EOA)和预编译合约。当操作码访问access set中不存在的地址时,它会将其添加到集合中。相关的操作码为 `EXTCODESIZE`、 `EXTCODECOPY`、 `EXTCODEHASH`、 `BALANCE`、 `CALL`、 `CALLCODE`、 `DELEGATECALL`、 `STATICCCALL`、 `CREATE`、 `CREATE2`和 `SELFDESTRUCT`。
* **touched\_storage\_slots**: 存储一组已访问的contract address及其slot key。它被初始化为空。当操作码访问access set中不存在的slot时,它会将其添加到其中。相关的操作码为 `SLOAD` 和 `SSTORE`
*注:如果发生context revert,access set也会恢复到它们在该context之前的状态*
| Opcode | Mnemonic | Description | Input(默认从左向右为:栈顶 => 向下) | Output | Gas |
| :-------------: | :------------: | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | :-------------------------------------------------------: | :------------------------------: | :----: |
| `0x00` | STOP | 结束合约执行并退出 | - | - | 0 |
| `0x01` | ADD | (u)int256,取模$2^{256}$ | `a,b` | `(a+b)` | 3 |
| `0x02` | MUL | (u)int256,取模$2^{256}$ | `a,b` | `(a*b)` | 5 |
| `0x03` | SUB | (u)int256,取模$2^{256}$ | `a,b` | `(a-b)` | 3 |
| `0x04` | DIV | 整除,uint256除法 | `a,b` | `(a/b)` | 5 |
| `0x05` | SDIV | 整除,int256除法 | `a,b` | `(a/b)` | 5 |
| `0x06` | MOD | uint256,取模$2^{256}$ | `a,b` | `(a%b)` | 5 |
| `0x07` | SMOD | int256,取模$2^{256}$ | `a,b` | `(a%b)` | 5 |
| `0x08` | ADDMOD | (u)int256加法,取模N | `a,b,N` | `(a+b)%N` | 8 |
| `0x09` | MULMOD | (u)int256乘法,取模N | `a,b,N` | `(a*b)%N` | 8 |
| `0x0a` | EXP | uint256指数结果,取模$2^{256}$ | `a,exp` | `a**exp` | 10+ |
| `0x0b` | SIGNEXTEND | 把`x`解释为b+1(0 <= `b` <= 31)字节有符号整数(二进制补码形式),然后把x的符号位复制填充,至扩展输出为32字节 | `b,x` | `y` | 5 |
| `0x0c` - `0x0f` | - | Unused | - | - | - |
| `0x10` | LT | uint256小于比较,满足返回1,不满足返回0 | `a,b` | `ab` | 3 |
| `0x12` | SLT | int256(补码)小于比较,满足返回1,不满足返回0 | `a,b` | `ab` | 3 |
| `0x14` | EQ | (u)int256相等比较,满足返回1,不满足返回0 | `a,b` | `a==b` | 3 |
| `0x15` | ISZERO | (u)int256零比较,满足返回1,不满足返回0 | `a` | `a==0` | 3 |
| `0x16` | AND | 256位的位与计算 | `a,b` | `a&b` | 3 |
| `0x17` | OR | 256位的位或计算 | `a,b` | \`a | b\` |
| `0x18` | XOR | 256位的异或计算 | `a,b` | `a^b` | |
| `0x19` | NOT | 256位的位取反计算 | `a` | `~a` | 3 |
| `0x1a` | BYTE | 返回(u)int256 `x`从最高字节开始的第`i`字节:`y=(x>>(248-i*8)) &0xFF` | `i,x` | `y` | 3 |
| `0x1b` | SHL | 256位左移位,新位置0:[EIP145](https://github.com/ethereum/EIPs/blob/master/EIPS/eip-145.md) | `shift,value` | `value<>shift` | 3 |
| `0x1d` | SAR | 考虑符号位的256右移位,新位符号位保持,其他位置0:[EIP145](https://github.com/ethereum/EIPs/blob/master/EIPS/eip-145.md) | `shift,value` | `value>>shift` | 3 |
| `0x20` | SHA3 | 从memory偏移`offset`的位置加载`size`的值作为入参,计算keccak256哈希 | `offset,size` | `hash` | 30+ |
| `0x21` - `0x2f` | - | Unused | - | - | - |
| `0x30` | ADDRESS | 获取当前执行合约的地址 | - | `address(this)` | 2 |
| `0x31` | BALANCE | 获取指定地址的余额,单位wei,地址不存在返回0,动态gas(依据[access sets](https://www.blocktempo.com/ethfans-ethereum-hard-fork-understanding-gas-costs-after-berlin/)) | `address` | `address.balance` | 100+ |
| `0x32` | ORIGIN | 获取交易发起方EOA的地址 | - | `tx.origin` | 2 |
| `0x33` | CALLER | 回去消息调用方地址 | - | `msg.sender` | 2 |
| `0x34` | CALLVALUE | 获取以wei为单位的消息调用携带金额 | - | `msg.value` | |
| `0x35` | CALLDATALOAD | 读取`calldata`(16进制表示的字节{偶数个})偏移`i`字节,**注意:若calldata不足32字节会右侧补0** | `i` | `calldata[i:]` | 3 |
| `0x36` | CALLDATASIZE | 返回以字节为单位的消息数据j长度 | - | `size(calldata)` | 2 |
| `0x37` | CALLDATACOPY | 拷贝`calldata`偏移`offset`字节的数据至偏移`destOffset`的memory位置 | `destOffset,offset,size` | - | 3+ |
| `0x38` | CODESIZE | 返回以字节为单位的,当前环境执行合约 (context中的code区域,实际即总字节码长度) 的代码(字节码)长度 | - | `size(address(this).code)` | 2 |
| `0x39` | CODECOPY | 拷贝`address(this).code`偏移`offset`字节的`size`大小的数据至偏移`destOffset`的memory位置 | `destOffset,offset,size` | - | 3+ |
| `0x3a` | GASPRICE | 返回当前执行交易的单位gas价格,以wei为单位 | - | `tx.gasprice` | 2 |
| `0x3b` | EXTCODESIZE | 获取指定`address`的`code`字节码长度,以字节为单位,动态gas(依据[access sets](https://www.blocktempo.com/ethfans-ethereum-hard-fork-understanding-gas-costs-after-berlin/)) | `address` | `size(address.code)` | 100+ |
| `0x3c` | EXTCODECOPY | 拷贝指定`address`字节码偏移`offset`字节的`size`大小的数据至偏移`destOffset`的memory位置,动态gas(依据[access sets](https://www.blocktempo.com/ethfans-ethereum-hard-fork-understanding-gas-costs-after-berlin/)) | `address,destOffset,offset,size` | - | 100+ |
| `0x3d` | RETURNDATASIZE | 返回最后一个外部调用(如call、delegatecall...)返回的数据(`return data`有专门的return value区域,并非如普通返回值在stack中)的长度,以字节为单位。[EIP 211](https://github.com/ethereum/EIPs/blob/master/EIPS/eip-211.md) | - | `size(return data)` | 2 |
| `0x3e` | RETURNDATACOPY | 拷贝`return data`偏移`offset`字节的`size`大小的数据至偏移`destOffset`的memory位置。[EIP 211](https://github.com/ethereum/EIPs/blob/master/EIPS/eip-211.md) | `destOffset,offset,size` | - | 3+ |
| `0x3f` | EXTCODEHASH | 返回指定`address`的`code`字节码的哈希,[EIP 1052](https://github.com/ethereum/EIPs/blob/master/EIPS/eip-1052.md),动态gas(依据[access sets](https://www.blocktempo.com/ethfans-ethereum-hard-fork-understanding-gas-costs-after-berlin/)) | `address` | `hash(address(this).code)` | 100+ |
| `0x40` | BLOCKHASH | 获得指定`blockNumber`的哈希,仅适用于最近的256个区块且不包括当前区块 | `blockNumber` | `blockhash(blockNumber)` | 20 |
| `0x41` | COINBASE | 获取当前区块的矿工的地址 | - | `block.coinbase` | 2 |
| `0x42` | TIMESTAMP | 获取当前区块的UNIX时间戳,以秒为单位 | - | `block.timestamp` | 2 |
| `0x43` | NUMBER | 获取当前区块号 | - | `block.number` | 2 |
| `0x44` | DIFFICULTY | 获取当前区块难度 | - | `block.difficulty` | 2 |
| `0x45` | GASLIMIT | 获取当前区块GAS上限 | - | `block.gaslimit` | 2 |
| `0x46` | CHAINID | 获取当前区块的chainId,[EIP 1344](https://github.com/ethereum/EIPs/blob/master/EIPS/eip-1344.md) | - | `block.chainid` | 2 |
| `0x47` | SELFBALANCE | 获取当前环境下,执行账户`address`的余额,Wei为单位 (对比BALANCE消耗更少的GAS) | - | `address(this).balance` | 5 |
| `0x48` | BASEFEE | 获取当前区块的基础gas fee,Wei为单位,[EIP 3198](https://eips.ethereum.org/EIPS/eip-3198) | - | `block.basefee` | 2 |
| `0x49` - `0x4f` | - | Unused | - | - | |
| `0x50` | POP | 弹出栈顶(u)int256值并丢弃 | - | - | 2 |
| `0x51` | **MLOAD** | 从memory偏移`offset`个字节的位置读取一个(u)int256到stack(值前面的0会舍弃),动态gas(会触发memory expansion,根据其判断) | `offset` | `value` | 3+ |
| `0x52` | **MSTORE** | 向memory偏移`offset`个字节的位置,写入一个(u)int256,动态gas(依据memory expansion) | `offset,value` | - | 3+ |
| `0x53` | MSTORE8 | 向memory偏移`offset`个字节的位置,写入一个(u)int8,动态gas(依据memory expansion) | `offset,value` | - | 3+ |
| `0x54` | **SLOAD** | 从storage的`slot[key]`读取一个(u)int256,如果该slot未被写入过则返回0,动态gas(依据[access sets](https://www.blocktempo.com/ethfans-ethereum-hard-fork-understanding-gas-costs-after-berlin/)) | `key` | `value` | 100+ |
| `0x55` | **SSTORE** | 向storage的`slot[key]`写入一个(u)int256,[动态gas比较复杂](https://www.evm.codes/),涉及gas refund等,首次写入消耗20000gas | `key,value` | - | 100+ |
| `0x56` | JUMP | 无条件跳转,即改变执行环境code中**PC** 至偏移`counter`字节的位置,跳转地点必须对应为JUMPDEST指令 | `counter` | - | 8 |
| `0x57` | JUMPI | 条件跳转,如果`b`不等于0,改变执行环境code中**PC**至偏移`counter`字节的位置。否则**PC**按正常顺序线性增加,跳转地点必须对应为JUMPDEST指令 | `counter,b` | - | 10 |
| `0x58` | PC | 一个指向字节码中下一个操作码的**指针**,由 EVM 执行。它是一个非负整数,实际是字节码中的**字节偏移数**。获取的是 “执行当前指令增量之前” (即不包含此次PC指令)的**PC**值。 | - | `counter` | 2 |
| `0x59` | MSIZE | 获取当前合约执行环境下的current memory (因为存在memory expansion) 大小,以字节为单位 | - | `size` | 2 |
| `0x5a` | GAS | 返回当前剩余的GAS | - | `gasleft()` | 2 |
| `0x5b` | JUMPDEST | 为跳转指令(JUMP/JUMPI)标记一个有效的目的地 | - | - | 1 |
| `0x5c` - `0x5f` | Unused | - | | | |
| `0x60` | PUSH1 | 将1字节的值压入栈顶,该系列指令后面紧跟待压入的数据如:`PUSH1 FF` | - | `value` | 3 |
| `0x61` | PUSH2 | 将2字节的值压入栈顶 | - | `value` | 3 |
| `0x62` | PUSH3 | 将3字节的值压入栈顶 | - | `value` | 3 |
| `0x63` | PUSH4 | 将4字节的值压入栈顶 | - | `value` | 3 |
| `0x64` | PUSH5 | 将5字节的值压入栈顶 | - | `value` | 3 |
| `0x65` | PUSH6 | 将6字节的值压入栈顶 | - | `value` | 3 |
| `0x66` | PUSH7 | 将7字节的值压入栈顶 | - | `value` | 3 |
| `0x67` | PUSH8 | 将8字节的值压入栈顶 | - | `value` | 3 |
| `0x68` | PUSH9 | 将9字节的值压入栈顶 | - | `value` | 3 |
| `0x69` | PUSH10 | 将10字节的值压入栈顶 | - | `value` | 3 |
| `0x6a` | PUSH11 | 将11字节的值压入栈顶 | - | `value` | 3 |
| `0x6b` | PUSH12 | 将12字节的值压入栈顶 | - | `value` | 3 |
| `0x6c` | PUSH13 | 将13字节的值压入栈顶 | - | `value` | 3 |
| `0x6d` | PUSH14 | 将14字节的值压入栈顶 | - | `value` | 3 |
| `0x6e` | PUSH15 | 将15字节的值压入栈顶 | - | `value` | 3 |
| `0x6f` | PUSH16 | 将16字节的值压入栈顶 | - | `value` | 3 |
| `0x70` | PUSH17 | 将17字节的值压入栈顶 | - | `value` | 3 |
| `0x71` | PUSH18 | 将18字节的值压入栈顶 | - | `value` | 3 |
| `0x72` | PUSH19 | 将19字节的值压入栈顶 | - | `value` | 3 |
| `0x73` | PUSH20 | 将20字节的值压入栈顶 | - | `value` | 3 |
| `0x74` | PUSH21 | 将21字节的值压入栈顶 | - | `value` | 3 |
| `0x75` | PUSH22 | 将22字节的值压入栈顶 | - | `value` | 3 |
| `0x76` | PUSH23 | 将23字节的值压入栈顶 | - | `value` | 3 |
| `0x77` | PUSH24 | 将24字节的值压入栈顶 | - | `value` | 3 |
| `0x78` | PUSH25 | 将25字节的值压入栈顶 | - | `value` | 3 |
| `0x79` | PUSH26 | 将25字节的值压入栈顶 | - | `value` | 3 |
| `0x7a` | PUSH27 | 将27字节的值压入栈顶 | - | `value` | 3 |
| `0x7b` | PUSH28 | 将28字节的值压入栈顶 | - | `value` | 3 |
| `0x7c` | PUSH29 | 将29字节的值压入栈顶 | - | `value` | 3 |
| `0x7d` | PUSH30 | 将30字节的值压入栈顶 | - | `value` | 3 |
| `0x7e` | PUSH31 | 将31字节的值压入栈顶 | - | `value` | 3 |
| `0x7f` | PUSH32 | (full word) 将32字节的值压入栈顶 | - | `value` | 3 |
| `0x80` | DUP1 | 取stack上的第1个值(1st 栈顶)并返回至栈顶 | `value` | `value,value` | 3 |
| `0x81` | DUP2 | 忽略stack上的前1个值,复制stack上的第2个值,并粘贴至栈顶 | `a,b` | `b,a,b` | 3 |
| `0x82` | DUP3 | 忽略stack上的前2个值,复制stack上的第3个值,并粘贴至栈顶 | `a,b,c` | `c,a,b,c` | 3 |
| `0x83` | DUP4 | 忽略stack上的前3个值,复制stack上的第4个值,并粘贴至栈顶 | `a,b,c,d` | `d,a,b,c,d` | 3 |
| `0x84` | DUP5 | 忽略stack上的前4 (=n-1)个值,复制stack上的第5 (=n)个值,并粘贴至栈顶 | `stack[0],...stack[n-1], stack[n]` | `stack[n],stack[0],... stack[n]` | 3 |
| `0x85` | DUP6 | 忽略stack上的前5 (=n-1)个值,复制stack上的第6 (=n)个值,并粘贴至栈顶 | `stack[0],...stack[n-1], stack[n]` | `stack[n],stack[0],... stack[n]` | 3 |
| `0x86` | DUP7 | 忽略stack上的前6 (=n-1)个值,复制stack上的第7(=n)个值,并粘贴至栈顶 | `stack[0],...stack[n-1], stack[n]` | `stack[n],stack[0],... stack[n]` | 3 |
| `0x87` | DUP8 | 忽略stack上的前7 (=n-1)个值,复制stack上的第8 (=n)个值,并粘贴至栈顶 | `stack[0],...stack[n-1], stack[n]` | `stack[n],stack[0],... stack[n]` | 3 |
| `0x88` | DUP9 | 忽略stack上的前8 (=n-1)个值,复制stack上的第9 (=n)个值,并粘贴至栈顶 | `stack[0],...stack[n-1], stack[n]` | `stack[n],stack[0],... stack[n]` | 3 |
| `0x89` | DUP10 | 忽略stack上的前9 (=n-1)个值,复制stack上的第10 (=n)个值,并粘贴至栈顶 | `stack[0],...stack[n-1], stack[n]` | `stack[n],stack[0],... stack[n]` | 3 |
| `0x8a` | DUP11 | 忽略stack上的前10 (=n-1)个值,复制stack上的第11 (=n)个值,并粘贴至栈顶 | `stack[0],...stack[n-1], stack[n]` | `stack[n],stack[0],... stack[n]` | 3 |
| `0x8b` | DUP12 | 忽略stack上的前11 (=n-1)个值,复制stack上的第12 (=n)个值,并粘贴至栈顶 | `stack[0],...stack[n-1], stack[n]` | `stack[n],stack[0],... stack[n]` | 3 |
| `0x8c` | DUP13 | 忽略stack上的前12 (=n-1)个值,复制stack上的第13 (=n)个值,并粘贴至栈顶 | `stack[0],...stack[n-1], stack[n]` | `stack[n],stack[0],... stack[n]` | 3 |
| `0x8d` | DUP14 | 忽略stack上的前13 (=n-1)个值,复制stack上的第14 (=n)个值,并粘贴至栈顶 | `stack[0],...stack[n-1], stack[n]` | `stack[n],stack[0],... stack[n]` | 3 |
| `0x8e` | DUP15 | 忽略stack上的前14 (=n-1)个值,复制stack上的第15 (=n)个值,并粘贴至栈顶 | `stack[0],...stack[n-1], stack[n]` | `stack[n],stack[0],... stack[n]` | 3 |
| `0x8f` | DUP16 | 忽略stack上的前15 (=n-1)个值,复制stack上的第16 (=n)个值,并粘贴至栈顶 | `stack[0],...stack[n-1], stack[n]` | `stack[n],stack[0],... stack[n]` | 3 |
| `0x90` | SWAP1 | 交换栈顶stack\[0]与(栈上2nd)stack\[1]的值 | `a,b` | `b,a` | 3 |
| `0x91` | SWAP2 | 交换栈顶stack\[0]与(栈上3rd)stack\[2]的值 | `a,b,c` | `c,b,a` | 3 |
| `0x92` | SWAP3 | 交换栈顶stack\[0]与(栈上4th)stack\[3]的值 | `a,...,b` | `b,...,a` | 3 |
| `0x93` | SWAP4 | 交换栈顶stack\[0]与(栈上5th)stack\[4]的值 | `a,...,b` | `b,...,a` | 3 |
| `0x94` | SWAP5 | 交换栈顶stack\[0]与(栈上6th)stack\[5]的值 | `a,...,b` | `b,...,a` | 3 |
| `0x95` | SWAP6 | 交换栈顶stack\[0]与(栈上7th)stack\[6]的值 | `a,...,b` | `b,...,a` | 3 |
| `0x96` | SWAP7 | 交换栈顶stack\[0]与(栈上8th)stack\[7]的值 | `a,...,b` | `b,...,a` | 3 |
| `0x97` | SWAP8 | 交换栈顶stack\[0]与(栈上9th)stack\[8]的值 | `a,...,b` | `b,...,a` | 3 |
| `0x98` | SWAP9 | 交换栈顶stack\[0]与(栈上10th)stack\[9]的值 | `a,...,b` | `b,...,a` | 3 |
| `0x99` | SWAP10 | 交换栈顶stack\[0]与(栈上11th)stack\[10]的值 | `a,...,b` | `b,...,a` | 3 |
| `0x9a` | SWAP11 | 交换栈顶stack\[0]与(栈上12th)stack\[11]的值 | `a,...,b` | `b,...,a` | 3 |
| `0x9b` | SWAP12 | 交换栈顶stack\[0]与(栈上13th)stack\[12]的值 | `a,...,b` | `b,...,a` | 3 |
| `0x9c` | SWAP13 | 交换栈顶stack\[0]与(栈上14th)stack\[13]的值 | `a,...,b` | `b,...,a` | 3 |
| `0x9d` | SWAP14 | 交换栈顶stack\[0]与(栈上15th)stack\[14]的值 | `a,...,b` | `b,...,a` | 3 |
| `0x9e` | SWAP15 | 交换栈顶stack\[0]与(栈上16th)stack\[15]的值 | `a,...,b` | `b,...,a` | 3 |
| `0x9f` | SWAP16 | 交换栈顶stack\[0]与(栈上17th)stack\[16]的值 | `a,...,b` | `b,...,a` | 3 |
| `0xa0` | LOG0 | 从memory偏移`offset`个字节的位置读取一个`size`大小作为data,无topic,输出日志 | `offset,size` | - | 375+ |
| `0xa1` | LOG1 | 从memory偏移`offset`个字节的位置读取一个`size`大小作为data,1个topic(32byte),输出日志 | `offset,size,topic` | - | 750+ |
| `0xa2` | LOG2 | 从memory偏移`offset`个字节的位置读取一个`size`大小作为data,2个topic,输出日志 | `offset,size,topic1,topic2` | - | 1125+ |
| `0xa3` | LOG3 | 从memory偏移`offset`个字节的位置读取一个`size`大小作为data,3个topic,输出日志 | `offset,size,topic1,topic2,topic3` | - | 1500+ |
| `0xa4` | LOG4 | 从memory偏移`offset`个字节的位置读取一个`size`大小作为data,4个topic,输出日志 | `offset,size,topic1,topic2,topic3,topic4` | - | 1875+ |
| `0xa5`-`0xaf` | - | Unused | - | - | - |
| `0xb0`-`0xbf` | - | Unused | - | - | - |
| `0xc0`-`0xcf` | - | Unused | - | - | - |
| `0xd0`-`0xdf` | - | Unused | - | - | - |
| `0xe0`-`0xef` | - | Unused | - | - | - |
| `0xf0` | CREATE | 从memory偏移`offset`个字节的位置读取一个`size`大小作为initialisation code来创建account,并发送`value`Wei,创建失败返回0 | `value,offset,size` | `address` | 32000+ |
| `0xf1` | CALL | 向账户`address`发出消息调用。argsOffset/Size制定了calldata从memory中读取的位置和大小,retOffset/Size制定了返回值存储于memory的条件。gas可用额度最多当前环境剩余gas的1/64,revert将返回0(注意,没有按预期执行目标账户code并不会revert),成功返回1 | `gas,address,value,argsOffset,argsSize,retOffset,retSize` | `success` | 100+ |
| `0xf2` | CALLCODE | 改变的是调用发起方的storage,其余功能同CALL | `gas,address,value,argsOffset,argsSize,retOffset,retSize` | `success` | 100+ |
| `0xf3` | RETURN | 停止执行并返回从memory偏移`offset`个字节的位置读取一个`size`大小的`return data` | `offset,size` | - | 0+ |
| `0xf4` | DELEGATECALL | 改变的是调用发起方的storage,msg.sender/msg.value为调用本方法的account(实际上是对CALLCODE的bugfix),无法转账,其余功能同CALL | `gas,address,argsOffset,argsSize,retOffset,retSize` | `success` | 100+ |
| `0xf5` | CREATE2 | 通过加`salt`的方式,以不同的[计算方式](https://github.com/AmazingAng/WTF-Solidity/tree/main/25_Create2),可以在account创建成功前得到地其address,其它同CREATE | `value,offset,size,salt` | `address` | 32000+ |
| `0xfa` | STATICCALL | 只读方法,不可修改state包括转账,即只能允许view和pure类型的函数调用,其他功能同CALL | `gas,address,argsOffset,argsSize,retOffset,retSize` | `success` | 100+ |
| `0xfd` | REVERT | REVERT ERROR:停止执行并回滚此次执行所改变的世界状态,返还unused gas给caller,并返回memory偏移`offset`个字节位置的`size`大小的`return data` | `offset,size` | - | 0+ |
| `0xfe` | INVALID | 特指的无效指令 ([等效于任何未在此目录的指令,实际上不是一个操作码](https://github.com/wolflo/evm-opcodes/issues/5)),等同于REVERT(0,0)指令的效果会回滚,不同的是将消耗掉所有remaining gas,[EIP141](https://learnblockchain.cn/docs/eips/eip-141.html#%E6%91%98%E8%A6%81) | - | - | NaN |
| `0xff` | SELFDESTRUCT | 停止执行并将当前账户标记为“待销毁”,将会在本次transaction最后执行,返回当前账户的balance至`address`(该行为无法被阻止,也不会报错) | `address` | - | 5000+ |
### ③EVM最小实现:模拟与Debug
> 尝试手动移植可参考[这里](https://zhuanlan.zhihu.com/p/440919875)
**1)EVM Toolkit(ETK)**
> 原文链接:
ETK是一个EVM 工具包,到目前位置,可以方便的将用mnemonic写的伪代码转化成字节码输出,同时也可以将字节码解码为mnemonic指令,核心指令为:
* Assembler: `eas`
汇编程序命令,将人类可读的mnemonic形式(如上文提到的)转换为 EVM 解释器期望的原始字节,以十六进制编码,并且可以配合`label`很方便的使用或编写代码。
> 手动计算跳转目的地地址将是一项非常无意义的任务,因此Assembler支持为代码中的特定位置分配特定的`label`,下例为一个无限循环mnemonic指令
>
> ```bash
> label0: # <- 标签名为 "label0",
> # 标签的value为偏移值,此处为0(因为在所有指令之前)
> jumpdest
> push1 label0 # <- 这里就可以直接Push对应标签,减少了计算偏移值的麻烦
>
> jump # 调整到offset=0位置的指令,对应jumpdest
> ```
```
eas input.etk output.hex
```
`Input` 参数(这里是 `input.etk`)是mnemonic程序集文件路径,`output.hex`是输出的字节码指令文件路径,以十六进制编码。如果省略了输出路径,则将汇编的指令写入标准输出(stdout)。
* Disassembler:`disease`
反汇编命令大致与汇编程序相反,它将一串EVM十六进制字节 (如`output.hex`)或其他格式的文件解析为mnemonic指令
* `--code, or -c`
对于简短的代码片段,可以解析直接在命令行上给出的十六进制字节码指令
```bash
disease --code 0x5b600056 # 解码命令行
```
* `--bin file, or -b`
将指定的二进制文件解释为mnemonic
```bash
disease --bin-file contract.bin # 解码二进制文件
```
* `--hex file, or -x`
将指定的EVM opcodes十六进制文件解释为mnemonic
```bash
disease --hex-file contract.hex # 解码十六进制文件
```
**2)hEVM**
> 原文链接:
hEVM 是以太虚拟机(EVM)的一个实现,该虚拟机专门用于智能合同的 symbolic execution、单元测试和调试EVM 字节码的操作,最初上作为 dapptools 项目的一部分。其以下功能有助于练习以太坊字节码的使用:
* 通过输入字节码执行智能合约并验证是否有错误
* 验证两组不同字节码是否等价
* 可视化调试任意的 evm 字节码的执行
* 通过 rpc 获取以太坊state
>
> 哈希算法的三个特性:
>
> 1. **唯一性**:输入任意内容可输出定长的内容,相同的输入一定会产出相同的输出,抗[碰撞](https://www.ruanyifeng.com/blog/2018/09/hash-collision-and-birthday-attack.html);
> 2. **雪崩效应**:即使一个极小的改变都会产生几乎完全不同的哈希值;
> 3. **单向性**:无法反向推导出pre-image(被哈希的内容的)。
| Address | Name | Description | Input(默认从左向右为:栈顶 => 向下) | Output | Gas |
| :-----: | :--------: | -------------------------------------------------------------------------------------------------------------------- | :-----------------------: | :-------: | :----: |
| `0x01` | ecRecover | 通过`signed transaction hash`及签名`v,r,s`,进行椭圆曲线数字签名算法(ECDSA)公钥恢复`signer address`,gas不足返回值为空 | `txhash,v,r,s` | `address` | 3000 |
| `0x02` | SHA2-256 | SHA256哈希算法(Bitcoin使用,属于SHA2系列),产生256位输出,gas不足返回值为空,对应Solidity中`sha256` | `data` | `hash` | 60+ |
| `0x03` | RIPEMD-160 | RIPEMD-160哈希算法 (Bitcoin使用),产生160位输出,gas不足返回值为空,对应Solidity中`ripemd160` | `data` | `hash` | 600+ |
| `0x04` | identity | 返回输入的`data`,通常用于复制内存块,gas不足返回值为空 | `data` | `data` | 15+ |
| `0x05` | modexp | 计算 $B^{E}\ mod \ M$ (`B/E/Msize`为对应值所占字节大小)的任意精度指数,E为0固定返回1,M为1固定返回0,gas不足返回值为空 | `Bsize,Esize,Msize,B,E,M` | `value` | 200+ |
| `0x06` | ecAdd | 椭圆曲线'alt\_bn128'上两点 (x,y) 的相加(ADD),无穷远点的 x 和 y 均为0,入参无效或gas不足返回值为空 | `x1,y1,x2,y2` | `x,y` | 150+ |
| `0x07` | ecMul | BN128椭圆曲线上点与标量相乘(MUL),s为标量scalar,无穷远点的 x 和 y 均为0 | `x1,y1,s` | `x,y` | 6000+ |
| `0x08` | ecPairing | BN128椭圆曲线的双线性函数配对操作,将用于[zk-SNARK](https://www.8btc.com/article/6783962)验证,入参无效或gas不足返回值为空 | `x1,y1,x2,y2...xk,yk` | `success` | 45000+ |
| `0x09` | blake2f | 实现blake2哈希函数,并在 BLAKE2 哈希算法中使用压缩函数 F ,使用的次数`rounds`([大端对齐](https://www.ruanyifeng.com/blog/2016/11/byte-order.html)) | `rounds,h,m,t,f` | `h` | 0+ |
**定义类知识点:**
* **Empty Account**:如果帐户的balance为0,nonce 为0且没有code,则定于该帐户为空账户
* **Intrinsic Gas**:每笔transaction的 “基本花销” 为21000 gas。在该基础上,部署一个contract需要花费 “基本花销” 32000 gas。之后,对于calldata,每0字节花费4gas,非0则花费16gas( **Istanbul分叉**之前是64gas)。这些费用需在执行任何opcodes或transfer之前被支付。
* **Gas Refund**:部分opcodes可以触发gas refund,从而降低交易的gas成本。然而,gas refund是在一笔transaction最后执行,这意味着transaction仍然需要足够的gas来运行完成(就好像不存在gas refund一样)。
此外,可以退还的gas数量也是有限的,不能超过整个transaction成本的一半(**London分叉**前),现在不能超过五分之一。并且从**London分叉**开始,只有 `SSTORE` 可能会触发gas refund,在此之前,SELFDESTRCT 也可以。
* [**Access Set**](https://github.com/wolflo/evm-opcodes/blob/main/gas.md):**Berlin分叉**后出现的概念,存在于access set的地址标识为'warm',不存在则标识为'cold',一些opcodes的动态开销与其有关。access set与每笔transaction绑定(而不是调用context)。access set中存在两个变量如下:
```go
// eth/tracers/loggers/access_list_tracer.go
type AccessListTracer struct {
excl map[common.Address]struct{} // Set of account to exclude from the list
list accessList // Set of accounts and storage slots touched
}
```
* **touched\_addresses**:存储一组当前transaction中被访问过的contract address。它被初始化为sender、receiver (CA/EOA)和预编译合约。当操作码访问access set中不存在的地址时,它会将其添加到集合中。相关的操作码为 `EXTCODESIZE`、 `EXTCODECOPY`、 `EXTCODEHASH`、 `BALANCE`、 `CALL`、 `CALLCODE`、 `DELEGATECALL`、 `STATICCCALL`、 `CREATE`、 `CREATE2`和 `SELFDESTRUCT`。
* **touched\_storage\_slots**: 存储一组已访问的contract address及其slot key。它被初始化为空。当操作码访问access set中不存在的slot时,它会将其添加到其中。相关的操作码为 `SLOAD` 和 `SSTORE`
*注:如果发生context revert,access set也会恢复到它们在该context之前的状态*
| Opcode | Mnemonic | Description | Input(默认从左向右为:栈顶 => 向下) | Output | Gas |
| :-------------: | :------------: | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | :-------------------------------------------------------: | :------------------------------: | :----: |
| `0x00` | STOP | 结束合约执行并退出 | - | - | 0 |
| `0x01` | ADD | (u)int256,取模$2^{256}$ | `a,b` | `(a+b)` | 3 |
| `0x02` | MUL | (u)int256,取模$2^{256}$ | `a,b` | `(a*b)` | 5 |
| `0x03` | SUB | (u)int256,取模$2^{256}$ | `a,b` | `(a-b)` | 3 |
| `0x04` | DIV | 整除,uint256除法 | `a,b` | `(a/b)` | 5 |
| `0x05` | SDIV | 整除,int256除法 | `a,b` | `(a/b)` | 5 |
| `0x06` | MOD | uint256,取模$2^{256}$ | `a,b` | `(a%b)` | 5 |
| `0x07` | SMOD | int256,取模$2^{256}$ | `a,b` | `(a%b)` | 5 |
| `0x08` | ADDMOD | (u)int256加法,取模N | `a,b,N` | `(a+b)%N` | 8 |
| `0x09` | MULMOD | (u)int256乘法,取模N | `a,b,N` | `(a*b)%N` | 8 |
| `0x0a` | EXP | uint256指数结果,取模$2^{256}$ | `a,exp` | `a**exp` | 10+ |
| `0x0b` | SIGNEXTEND | 把`x`解释为b+1(0 <= `b` <= 31)字节有符号整数(二进制补码形式),然后把x的符号位复制填充,至扩展输出为32字节 | `b,x` | `y` | 5 |
| `0x0c` - `0x0f` | - | Unused | - | - | - |
| `0x10` | LT | uint256小于比较,满足返回1,不满足返回0 | `a,b` | `ab` | 3 |
| `0x12` | SLT | int256(补码)小于比较,满足返回1,不满足返回0 | `a,b` | `ab` | 3 |
| `0x14` | EQ | (u)int256相等比较,满足返回1,不满足返回0 | `a,b` | `a==b` | 3 |
| `0x15` | ISZERO | (u)int256零比较,满足返回1,不满足返回0 | `a` | `a==0` | 3 |
| `0x16` | AND | 256位的位与计算 | `a,b` | `a&b` | 3 |
| `0x17` | OR | 256位的位或计算 | `a,b` | \`a | b\` |
| `0x18` | XOR | 256位的异或计算 | `a,b` | `a^b` | |
| `0x19` | NOT | 256位的位取反计算 | `a` | `~a` | 3 |
| `0x1a` | BYTE | 返回(u)int256 `x`从最高字节开始的第`i`字节:`y=(x>>(248-i*8)) &0xFF` | `i,x` | `y` | 3 |
| `0x1b` | SHL | 256位左移位,新位置0:[EIP145](https://github.com/ethereum/EIPs/blob/master/EIPS/eip-145.md) | `shift,value` | `value<>shift` | 3 |
| `0x1d` | SAR | 考虑符号位的256右移位,新位符号位保持,其他位置0:[EIP145](https://github.com/ethereum/EIPs/blob/master/EIPS/eip-145.md) | `shift,value` | `value>>shift` | 3 |
| `0x20` | SHA3 | 从memory偏移`offset`的位置加载`size`的值作为入参,计算keccak256哈希 | `offset,size` | `hash` | 30+ |
| `0x21` - `0x2f` | - | Unused | - | - | - |
| `0x30` | ADDRESS | 获取当前执行合约的地址 | - | `address(this)` | 2 |
| `0x31` | BALANCE | 获取指定地址的余额,单位wei,地址不存在返回0,动态gas(依据[access sets](https://www.blocktempo.com/ethfans-ethereum-hard-fork-understanding-gas-costs-after-berlin/)) | `address` | `address.balance` | 100+ |
| `0x32` | ORIGIN | 获取交易发起方EOA的地址 | - | `tx.origin` | 2 |
| `0x33` | CALLER | 回去消息调用方地址 | - | `msg.sender` | 2 |
| `0x34` | CALLVALUE | 获取以wei为单位的消息调用携带金额 | - | `msg.value` | |
| `0x35` | CALLDATALOAD | 读取`calldata`(16进制表示的字节{偶数个})偏移`i`字节,**注意:若calldata不足32字节会右侧补0** | `i` | `calldata[i:]` | 3 |
| `0x36` | CALLDATASIZE | 返回以字节为单位的消息数据j长度 | - | `size(calldata)` | 2 |
| `0x37` | CALLDATACOPY | 拷贝`calldata`偏移`offset`字节的数据至偏移`destOffset`的memory位置 | `destOffset,offset,size` | - | 3+ |
| `0x38` | CODESIZE | 返回以字节为单位的,当前环境执行合约 (context中的code区域,实际即总字节码长度) 的代码(字节码)长度 | - | `size(address(this).code)` | 2 |
| `0x39` | CODECOPY | 拷贝`address(this).code`偏移`offset`字节的`size`大小的数据至偏移`destOffset`的memory位置 | `destOffset,offset,size` | - | 3+ |
| `0x3a` | GASPRICE | 返回当前执行交易的单位gas价格,以wei为单位 | - | `tx.gasprice` | 2 |
| `0x3b` | EXTCODESIZE | 获取指定`address`的`code`字节码长度,以字节为单位,动态gas(依据[access sets](https://www.blocktempo.com/ethfans-ethereum-hard-fork-understanding-gas-costs-after-berlin/)) | `address` | `size(address.code)` | 100+ |
| `0x3c` | EXTCODECOPY | 拷贝指定`address`字节码偏移`offset`字节的`size`大小的数据至偏移`destOffset`的memory位置,动态gas(依据[access sets](https://www.blocktempo.com/ethfans-ethereum-hard-fork-understanding-gas-costs-after-berlin/)) | `address,destOffset,offset,size` | - | 100+ |
| `0x3d` | RETURNDATASIZE | 返回最后一个外部调用(如call、delegatecall...)返回的数据(`return data`有专门的return value区域,并非如普通返回值在stack中)的长度,以字节为单位。[EIP 211](https://github.com/ethereum/EIPs/blob/master/EIPS/eip-211.md) | - | `size(return data)` | 2 |
| `0x3e` | RETURNDATACOPY | 拷贝`return data`偏移`offset`字节的`size`大小的数据至偏移`destOffset`的memory位置。[EIP 211](https://github.com/ethereum/EIPs/blob/master/EIPS/eip-211.md) | `destOffset,offset,size` | - | 3+ |
| `0x3f` | EXTCODEHASH | 返回指定`address`的`code`字节码的哈希,[EIP 1052](https://github.com/ethereum/EIPs/blob/master/EIPS/eip-1052.md),动态gas(依据[access sets](https://www.blocktempo.com/ethfans-ethereum-hard-fork-understanding-gas-costs-after-berlin/)) | `address` | `hash(address(this).code)` | 100+ |
| `0x40` | BLOCKHASH | 获得指定`blockNumber`的哈希,仅适用于最近的256个区块且不包括当前区块 | `blockNumber` | `blockhash(blockNumber)` | 20 |
| `0x41` | COINBASE | 获取当前区块的矿工的地址 | - | `block.coinbase` | 2 |
| `0x42` | TIMESTAMP | 获取当前区块的UNIX时间戳,以秒为单位 | - | `block.timestamp` | 2 |
| `0x43` | NUMBER | 获取当前区块号 | - | `block.number` | 2 |
| `0x44` | DIFFICULTY | 获取当前区块难度 | - | `block.difficulty` | 2 |
| `0x45` | GASLIMIT | 获取当前区块GAS上限 | - | `block.gaslimit` | 2 |
| `0x46` | CHAINID | 获取当前区块的chainId,[EIP 1344](https://github.com/ethereum/EIPs/blob/master/EIPS/eip-1344.md) | - | `block.chainid` | 2 |
| `0x47` | SELFBALANCE | 获取当前环境下,执行账户`address`的余额,Wei为单位 (对比BALANCE消耗更少的GAS) | - | `address(this).balance` | 5 |
| `0x48` | BASEFEE | 获取当前区块的基础gas fee,Wei为单位,[EIP 3198](https://eips.ethereum.org/EIPS/eip-3198) | - | `block.basefee` | 2 |
| `0x49` - `0x4f` | - | Unused | - | - | |
| `0x50` | POP | 弹出栈顶(u)int256值并丢弃 | - | - | 2 |
| `0x51` | **MLOAD** | 从memory偏移`offset`个字节的位置读取一个(u)int256到stack(值前面的0会舍弃),动态gas(会触发memory expansion,根据其判断) | `offset` | `value` | 3+ |
| `0x52` | **MSTORE** | 向memory偏移`offset`个字节的位置,写入一个(u)int256,动态gas(依据memory expansion) | `offset,value` | - | 3+ |
| `0x53` | MSTORE8 | 向memory偏移`offset`个字节的位置,写入一个(u)int8,动态gas(依据memory expansion) | `offset,value` | - | 3+ |
| `0x54` | **SLOAD** | 从storage的`slot[key]`读取一个(u)int256,如果该slot未被写入过则返回0,动态gas(依据[access sets](https://www.blocktempo.com/ethfans-ethereum-hard-fork-understanding-gas-costs-after-berlin/)) | `key` | `value` | 100+ |
| `0x55` | **SSTORE** | 向storage的`slot[key]`写入一个(u)int256,[动态gas比较复杂](https://www.evm.codes/),涉及gas refund等,首次写入消耗20000gas | `key,value` | - | 100+ |
| `0x56` | JUMP | 无条件跳转,即改变执行环境code中**PC** 至偏移`counter`字节的位置,跳转地点必须对应为JUMPDEST指令 | `counter` | - | 8 |
| `0x57` | JUMPI | 条件跳转,如果`b`不等于0,改变执行环境code中**PC**至偏移`counter`字节的位置。否则**PC**按正常顺序线性增加,跳转地点必须对应为JUMPDEST指令 | `counter,b` | - | 10 |
| `0x58` | PC | 一个指向字节码中下一个操作码的**指针**,由 EVM 执行。它是一个非负整数,实际是字节码中的**字节偏移数**。获取的是 “执行当前指令增量之前” (即不包含此次PC指令)的**PC**值。 | - | `counter` | 2 |
| `0x59` | MSIZE | 获取当前合约执行环境下的current memory (因为存在memory expansion) 大小,以字节为单位 | - | `size` | 2 |
| `0x5a` | GAS | 返回当前剩余的GAS | - | `gasleft()` | 2 |
| `0x5b` | JUMPDEST | 为跳转指令(JUMP/JUMPI)标记一个有效的目的地 | - | - | 1 |
| `0x5c` - `0x5f` | Unused | - | | | |
| `0x60` | PUSH1 | 将1字节的值压入栈顶,该系列指令后面紧跟待压入的数据如:`PUSH1 FF` | - | `value` | 3 |
| `0x61` | PUSH2 | 将2字节的值压入栈顶 | - | `value` | 3 |
| `0x62` | PUSH3 | 将3字节的值压入栈顶 | - | `value` | 3 |
| `0x63` | PUSH4 | 将4字节的值压入栈顶 | - | `value` | 3 |
| `0x64` | PUSH5 | 将5字节的值压入栈顶 | - | `value` | 3 |
| `0x65` | PUSH6 | 将6字节的值压入栈顶 | - | `value` | 3 |
| `0x66` | PUSH7 | 将7字节的值压入栈顶 | - | `value` | 3 |
| `0x67` | PUSH8 | 将8字节的值压入栈顶 | - | `value` | 3 |
| `0x68` | PUSH9 | 将9字节的值压入栈顶 | - | `value` | 3 |
| `0x69` | PUSH10 | 将10字节的值压入栈顶 | - | `value` | 3 |
| `0x6a` | PUSH11 | 将11字节的值压入栈顶 | - | `value` | 3 |
| `0x6b` | PUSH12 | 将12字节的值压入栈顶 | - | `value` | 3 |
| `0x6c` | PUSH13 | 将13字节的值压入栈顶 | - | `value` | 3 |
| `0x6d` | PUSH14 | 将14字节的值压入栈顶 | - | `value` | 3 |
| `0x6e` | PUSH15 | 将15字节的值压入栈顶 | - | `value` | 3 |
| `0x6f` | PUSH16 | 将16字节的值压入栈顶 | - | `value` | 3 |
| `0x70` | PUSH17 | 将17字节的值压入栈顶 | - | `value` | 3 |
| `0x71` | PUSH18 | 将18字节的值压入栈顶 | - | `value` | 3 |
| `0x72` | PUSH19 | 将19字节的值压入栈顶 | - | `value` | 3 |
| `0x73` | PUSH20 | 将20字节的值压入栈顶 | - | `value` | 3 |
| `0x74` | PUSH21 | 将21字节的值压入栈顶 | - | `value` | 3 |
| `0x75` | PUSH22 | 将22字节的值压入栈顶 | - | `value` | 3 |
| `0x76` | PUSH23 | 将23字节的值压入栈顶 | - | `value` | 3 |
| `0x77` | PUSH24 | 将24字节的值压入栈顶 | - | `value` | 3 |
| `0x78` | PUSH25 | 将25字节的值压入栈顶 | - | `value` | 3 |
| `0x79` | PUSH26 | 将25字节的值压入栈顶 | - | `value` | 3 |
| `0x7a` | PUSH27 | 将27字节的值压入栈顶 | - | `value` | 3 |
| `0x7b` | PUSH28 | 将28字节的值压入栈顶 | - | `value` | 3 |
| `0x7c` | PUSH29 | 将29字节的值压入栈顶 | - | `value` | 3 |
| `0x7d` | PUSH30 | 将30字节的值压入栈顶 | - | `value` | 3 |
| `0x7e` | PUSH31 | 将31字节的值压入栈顶 | - | `value` | 3 |
| `0x7f` | PUSH32 | (full word) 将32字节的值压入栈顶 | - | `value` | 3 |
| `0x80` | DUP1 | 取stack上的第1个值(1st 栈顶)并返回至栈顶 | `value` | `value,value` | 3 |
| `0x81` | DUP2 | 忽略stack上的前1个值,复制stack上的第2个值,并粘贴至栈顶 | `a,b` | `b,a,b` | 3 |
| `0x82` | DUP3 | 忽略stack上的前2个值,复制stack上的第3个值,并粘贴至栈顶 | `a,b,c` | `c,a,b,c` | 3 |
| `0x83` | DUP4 | 忽略stack上的前3个值,复制stack上的第4个值,并粘贴至栈顶 | `a,b,c,d` | `d,a,b,c,d` | 3 |
| `0x84` | DUP5 | 忽略stack上的前4 (=n-1)个值,复制stack上的第5 (=n)个值,并粘贴至栈顶 | `stack[0],...stack[n-1], stack[n]` | `stack[n],stack[0],... stack[n]` | 3 |
| `0x85` | DUP6 | 忽略stack上的前5 (=n-1)个值,复制stack上的第6 (=n)个值,并粘贴至栈顶 | `stack[0],...stack[n-1], stack[n]` | `stack[n],stack[0],... stack[n]` | 3 |
| `0x86` | DUP7 | 忽略stack上的前6 (=n-1)个值,复制stack上的第7(=n)个值,并粘贴至栈顶 | `stack[0],...stack[n-1], stack[n]` | `stack[n],stack[0],... stack[n]` | 3 |
| `0x87` | DUP8 | 忽略stack上的前7 (=n-1)个值,复制stack上的第8 (=n)个值,并粘贴至栈顶 | `stack[0],...stack[n-1], stack[n]` | `stack[n],stack[0],... stack[n]` | 3 |
| `0x88` | DUP9 | 忽略stack上的前8 (=n-1)个值,复制stack上的第9 (=n)个值,并粘贴至栈顶 | `stack[0],...stack[n-1], stack[n]` | `stack[n],stack[0],... stack[n]` | 3 |
| `0x89` | DUP10 | 忽略stack上的前9 (=n-1)个值,复制stack上的第10 (=n)个值,并粘贴至栈顶 | `stack[0],...stack[n-1], stack[n]` | `stack[n],stack[0],... stack[n]` | 3 |
| `0x8a` | DUP11 | 忽略stack上的前10 (=n-1)个值,复制stack上的第11 (=n)个值,并粘贴至栈顶 | `stack[0],...stack[n-1], stack[n]` | `stack[n],stack[0],... stack[n]` | 3 |
| `0x8b` | DUP12 | 忽略stack上的前11 (=n-1)个值,复制stack上的第12 (=n)个值,并粘贴至栈顶 | `stack[0],...stack[n-1], stack[n]` | `stack[n],stack[0],... stack[n]` | 3 |
| `0x8c` | DUP13 | 忽略stack上的前12 (=n-1)个值,复制stack上的第13 (=n)个值,并粘贴至栈顶 | `stack[0],...stack[n-1], stack[n]` | `stack[n],stack[0],... stack[n]` | 3 |
| `0x8d` | DUP14 | 忽略stack上的前13 (=n-1)个值,复制stack上的第14 (=n)个值,并粘贴至栈顶 | `stack[0],...stack[n-1], stack[n]` | `stack[n],stack[0],... stack[n]` | 3 |
| `0x8e` | DUP15 | 忽略stack上的前14 (=n-1)个值,复制stack上的第15 (=n)个值,并粘贴至栈顶 | `stack[0],...stack[n-1], stack[n]` | `stack[n],stack[0],... stack[n]` | 3 |
| `0x8f` | DUP16 | 忽略stack上的前15 (=n-1)个值,复制stack上的第16 (=n)个值,并粘贴至栈顶 | `stack[0],...stack[n-1], stack[n]` | `stack[n],stack[0],... stack[n]` | 3 |
| `0x90` | SWAP1 | 交换栈顶stack\[0]与(栈上2nd)stack\[1]的值 | `a,b` | `b,a` | 3 |
| `0x91` | SWAP2 | 交换栈顶stack\[0]与(栈上3rd)stack\[2]的值 | `a,b,c` | `c,b,a` | 3 |
| `0x92` | SWAP3 | 交换栈顶stack\[0]与(栈上4th)stack\[3]的值 | `a,...,b` | `b,...,a` | 3 |
| `0x93` | SWAP4 | 交换栈顶stack\[0]与(栈上5th)stack\[4]的值 | `a,...,b` | `b,...,a` | 3 |
| `0x94` | SWAP5 | 交换栈顶stack\[0]与(栈上6th)stack\[5]的值 | `a,...,b` | `b,...,a` | 3 |
| `0x95` | SWAP6 | 交换栈顶stack\[0]与(栈上7th)stack\[6]的值 | `a,...,b` | `b,...,a` | 3 |
| `0x96` | SWAP7 | 交换栈顶stack\[0]与(栈上8th)stack\[7]的值 | `a,...,b` | `b,...,a` | 3 |
| `0x97` | SWAP8 | 交换栈顶stack\[0]与(栈上9th)stack\[8]的值 | `a,...,b` | `b,...,a` | 3 |
| `0x98` | SWAP9 | 交换栈顶stack\[0]与(栈上10th)stack\[9]的值 | `a,...,b` | `b,...,a` | 3 |
| `0x99` | SWAP10 | 交换栈顶stack\[0]与(栈上11th)stack\[10]的值 | `a,...,b` | `b,...,a` | 3 |
| `0x9a` | SWAP11 | 交换栈顶stack\[0]与(栈上12th)stack\[11]的值 | `a,...,b` | `b,...,a` | 3 |
| `0x9b` | SWAP12 | 交换栈顶stack\[0]与(栈上13th)stack\[12]的值 | `a,...,b` | `b,...,a` | 3 |
| `0x9c` | SWAP13 | 交换栈顶stack\[0]与(栈上14th)stack\[13]的值 | `a,...,b` | `b,...,a` | 3 |
| `0x9d` | SWAP14 | 交换栈顶stack\[0]与(栈上15th)stack\[14]的值 | `a,...,b` | `b,...,a` | 3 |
| `0x9e` | SWAP15 | 交换栈顶stack\[0]与(栈上16th)stack\[15]的值 | `a,...,b` | `b,...,a` | 3 |
| `0x9f` | SWAP16 | 交换栈顶stack\[0]与(栈上17th)stack\[16]的值 | `a,...,b` | `b,...,a` | 3 |
| `0xa0` | LOG0 | 从memory偏移`offset`个字节的位置读取一个`size`大小作为data,无topic,输出日志 | `offset,size` | - | 375+ |
| `0xa1` | LOG1 | 从memory偏移`offset`个字节的位置读取一个`size`大小作为data,1个topic(32byte),输出日志 | `offset,size,topic` | - | 750+ |
| `0xa2` | LOG2 | 从memory偏移`offset`个字节的位置读取一个`size`大小作为data,2个topic,输出日志 | `offset,size,topic1,topic2` | - | 1125+ |
| `0xa3` | LOG3 | 从memory偏移`offset`个字节的位置读取一个`size`大小作为data,3个topic,输出日志 | `offset,size,topic1,topic2,topic3` | - | 1500+ |
| `0xa4` | LOG4 | 从memory偏移`offset`个字节的位置读取一个`size`大小作为data,4个topic,输出日志 | `offset,size,topic1,topic2,topic3,topic4` | - | 1875+ |
| `0xa5`-`0xaf` | - | Unused | - | - | - |
| `0xb0`-`0xbf` | - | Unused | - | - | - |
| `0xc0`-`0xcf` | - | Unused | - | - | - |
| `0xd0`-`0xdf` | - | Unused | - | - | - |
| `0xe0`-`0xef` | - | Unused | - | - | - |
| `0xf0` | CREATE | 从memory偏移`offset`个字节的位置读取一个`size`大小作为initialisation code来创建account,并发送`value`Wei,创建失败返回0 | `value,offset,size` | `address` | 32000+ |
| `0xf1` | CALL | 向账户`address`发出消息调用。argsOffset/Size制定了calldata从memory中读取的位置和大小,retOffset/Size制定了返回值存储于memory的条件。gas可用额度最多当前环境剩余gas的1/64,revert将返回0(注意,没有按预期执行目标账户code并不会revert),成功返回1 | `gas,address,value,argsOffset,argsSize,retOffset,retSize` | `success` | 100+ |
| `0xf2` | CALLCODE | 改变的是调用发起方的storage,其余功能同CALL | `gas,address,value,argsOffset,argsSize,retOffset,retSize` | `success` | 100+ |
| `0xf3` | RETURN | 停止执行并返回从memory偏移`offset`个字节的位置读取一个`size`大小的`return data` | `offset,size` | - | 0+ |
| `0xf4` | DELEGATECALL | 改变的是调用发起方的storage,msg.sender/msg.value为调用本方法的account(实际上是对CALLCODE的bugfix),无法转账,其余功能同CALL | `gas,address,argsOffset,argsSize,retOffset,retSize` | `success` | 100+ |
| `0xf5` | CREATE2 | 通过加`salt`的方式,以不同的[计算方式](https://github.com/AmazingAng/WTF-Solidity/tree/main/25_Create2),可以在account创建成功前得到地其address,其它同CREATE | `value,offset,size,salt` | `address` | 32000+ |
| `0xfa` | STATICCALL | 只读方法,不可修改state包括转账,即只能允许view和pure类型的函数调用,其他功能同CALL | `gas,address,argsOffset,argsSize,retOffset,retSize` | `success` | 100+ |
| `0xfd` | REVERT | REVERT ERROR:停止执行并回滚此次执行所改变的世界状态,返还unused gas给caller,并返回memory偏移`offset`个字节位置的`size`大小的`return data` | `offset,size` | - | 0+ |
| `0xfe` | INVALID | 特指的无效指令 ([等效于任何未在此目录的指令,实际上不是一个操作码](https://github.com/wolflo/evm-opcodes/issues/5)),等同于REVERT(0,0)指令的效果会回滚,不同的是将消耗掉所有remaining gas,[EIP141](https://learnblockchain.cn/docs/eips/eip-141.html#%E6%91%98%E8%A6%81) | - | - | NaN |
| `0xff` | SELFDESTRUCT | 停止执行并将当前账户标记为“待销毁”,将会在本次transaction最后执行,返回当前账户的balance至`address`(该行为无法被阻止,也不会报错) | `address` | - | 5000+ |
### ③EVM最小实现:模拟与Debug
> 尝试手动移植可参考[这里](https://zhuanlan.zhihu.com/p/440919875)
**1)EVM Toolkit(ETK)**
> 原文链接:
ETK是一个EVM 工具包,到目前位置,可以方便的将用mnemonic写的伪代码转化成字节码输出,同时也可以将字节码解码为mnemonic指令,核心指令为:
* Assembler: `eas`
汇编程序命令,将人类可读的mnemonic形式(如上文提到的)转换为 EVM 解释器期望的原始字节,以十六进制编码,并且可以配合`label`很方便的使用或编写代码。
> 手动计算跳转目的地地址将是一项非常无意义的任务,因此Assembler支持为代码中的特定位置分配特定的`label`,下例为一个无限循环mnemonic指令
>
> ```bash
> label0: # <- 标签名为 "label0",
> # 标签的value为偏移值,此处为0(因为在所有指令之前)
> jumpdest
> push1 label0 # <- 这里就可以直接Push对应标签,减少了计算偏移值的麻烦
>
> jump # 调整到offset=0位置的指令,对应jumpdest
> ```
```
eas input.etk output.hex
```
`Input` 参数(这里是 `input.etk`)是mnemonic程序集文件路径,`output.hex`是输出的字节码指令文件路径,以十六进制编码。如果省略了输出路径,则将汇编的指令写入标准输出(stdout)。
* Disassembler:`disease`
反汇编命令大致与汇编程序相反,它将一串EVM十六进制字节 (如`output.hex`)或其他格式的文件解析为mnemonic指令
* `--code, or -c`
对于简短的代码片段,可以解析直接在命令行上给出的十六进制字节码指令
```bash
disease --code 0x5b600056 # 解码命令行
```
* `--bin file, or -b`
将指定的二进制文件解释为mnemonic
```bash
disease --bin-file contract.bin # 解码二进制文件
```
* `--hex file, or -x`
将指定的EVM opcodes十六进制文件解释为mnemonic
```bash
disease --hex-file contract.hex # 解码十六进制文件
```
**2)hEVM**
> 原文链接:
hEVM 是以太虚拟机(EVM)的一个实现,该虚拟机专门用于智能合同的 symbolic execution、单元测试和调试EVM 字节码的操作,最初上作为 dapptools 项目的一部分。其以下功能有助于练习以太坊字节码的使用:
* 通过输入字节码执行智能合约并验证是否有错误
* 验证两组不同字节码是否等价
* 可视化调试任意的 evm 字节码的执行
* 通过 rpc 获取以太坊state